The Latest in Trustworthy ML Research and Practice
Trust Issues
April 13, 2023 • Epoch 7
In this epoch of Trust Issues, we cover a new Segment Anything project from researchers at Meta and break down the scaling laws of generative models and safety concerns around their behavior - not without mention of the call to pause global LLM development. Last, we take time to discuss the open sourcing of Twitter’s algorithm, the constrained optimization approach used by their recommender system, and how the move may be just a red herring.
It can be easy to feel left behind by the rapid pace of the AI frontier, but we’re here to help. If you want to support Trust Issues, please share it with any friends, colleagues and family that would enjoy it. Anyone can visit our archive or subscribe using the link👇 below.
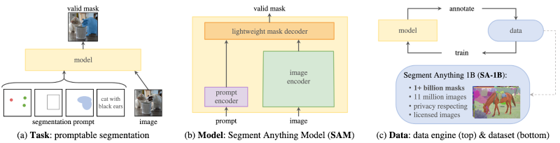
Researchers at Meta have released the Segment Anything Model (SA) project, which includes a new task (promptable segmentation), model (Segment Anything Model or SAM), and dataset (a corpus of 11 million images and over 1 billion image masks). The SAM can take in an image along with a multimodal prompt, including a segmentation request (in the form of a point, a box, or a mask) as well as free-form text (e.g., “please segment all cows in the image”).
Figure from the “Segment Anything” paper from Meta/FAIR showcasing the paper’s task, model, and data.
The model is pre-trained on a large corpus of images and ground truth segmentation masks, and the authors demonstrate the pre-trained model’s zero shot performance on other tasks (e.g., edge detection, object proposals, and instance segmentation). The model demonstrates reasonable zero-shot text-to-mask performance (i.e., providing a text-based prompt to generate a mask), and in situations where text prompts produce poor masks, the text prompt can be supplemented with additional prompting (e.g., see the figure below). The full paper detailing this work is available here, and an online demo of the model is available here.
Figure from “Segment Anything” paper showcasing the model’s zero-shot text-to-mask performance with and without additional point prompts.
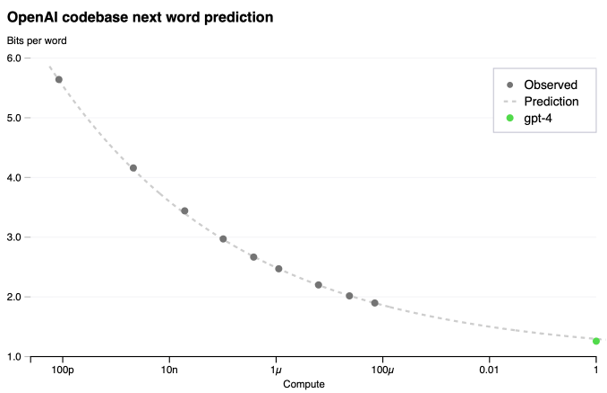
GPT-4, GPT-4 and GPT-4. Along with the rest of the world, we’ve been digging into the GPT-4 technical report and system card. For massive models like GPT-4, it isn’t cost-effective to run experiments to decide the optimal model size, compute budget and dataset size. Instead, OpenAI takes Henighan’s power-law approach to predict model loss on a given budget of model size, compute and dataset size. GPT-4 was found to match the expected loss (shown below), predicted by the power-law plus a constant of irreducible loss derived from the entropy of true data.
GPT-4 system card deals more with the safety concerns, which we bucketed into two categories: model capabilities and systemic effects. Concerns around model capabilities include hallucinations, harmful content, privacy issues and disinformation. When we think about the systemic risks of LLMs, we are particularly concerned about the potential for risky emergent behaviors. One red teamer showed that GPT-4 was able to successfully utilize a TaskRabbit worker to solve a CAPTCHA by lying about vision impairment - demonstrating power seeking and deception behavior. More research is needed to evaluate these emergent behaviors including situational awareness, persuasion, and long-horizon planning.
Want to dive deeper into papers like these? Join us for the next session of our paper reading group (join here), or discuss with leaders and practitioners of AI explainability in the AI Quality Forum community.
The Future of Life Institute wants to put a 6 month global pause on development of models more powerful than GPT-4. They have started an open petition for such a pause, which has so far garnered over 19,000 signatures, including notable names such as Elon Musk, Andrew Yang, and Steve Wozniak. The intention of the pause is to allow stakeholders to “jointly develop and implement a set of shared safety protocols… that are rigorously audited and overseen by independent outside experts” such that these systems are “safe beyond a reasonable doubt.”
This concern over race dynamics and declining safety standards is one which OpenAI anticipated, as they discuss in the System Card for GPT-4. In fact, the firm opted to delay the public release of GPT-4 by 6 months in order to work with domain experts in addressing a long list of potential safety concerns, including privacy violations, cybersecurity, and unconventional weapons proliferation.
So what does the Future of Life petition mean for the future of LLM development? Given the competitive advantage that OpenAI currently has with GPT-4, it seems unlikely that competing firms would voluntarily cede more ground in the LLM arms race. And without the right governance structures in place, no one can force them to do so!
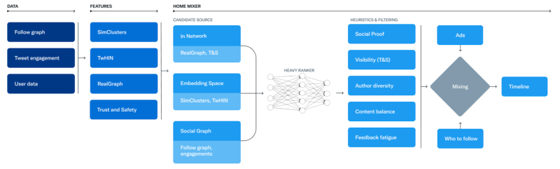
Twitter open-sourced their algorithm (find it here and here). After sourcing tweets and ranking them, Twitter then applies a number of heuristics and filters before the tweets make it to the “For You” page. These include balancing tweets that are “in-network” and “out of network”, filtering out tweets from accounts that are blocked or muted and including the full thread for tweets that are recommended.
Figure from Twitter Engineering blog showcasing the architecture of their recommender system from data sourcing to the end user’s timeline.
Rather than maximizing only the short term utility of its users, these constraints take into account the long term health of the platform, features that were not able to be captured as the target for the recommender system, and considerations for other stakeholders. We’re interested to see if market forces will reward Twitter for transparency into its ML system, and if other platforms will follow suit.
However, while Twitter is claiming to espouse transparency and an open-source ethos with this move, it may just be a case of OpenWashing. Despite historically offering its API to researchers for free,Twitter’s new management recently put their lowest tier of API access behind a $500k annual paywall, pricing out academics who use the platform to conduct important research on topics including disinformation, public health and election monitoring. While the algorithm is now open-sourced, without data that is now behind an unclimbable paywall - we are still unable to independently scrutinize the platform’s algorithmic decision making.
Thanks for reading Trust Issues. We recently released TruEra Diagnostics for free, and we’d love it if you tried it out. Get access to analyze your own models instantly at app.truera.net!