In this issue: We explore more efficient ways of training models and constructing augmented language model systems. We also ponder upward and downward pressure on AI.
The Latest in Trustworthy ML Research and Practice
Trust Issues
June 8, 2023 • Epoch 9
TruLens for LLMs launched just two weeks ago, and we’re already rolling out some exciting updates. This open source package helps you to objectively measure the quality and effectiveness of your LLM-based applications using feedback functions. We've added a ton of new features to TruLens to fit easily into your LLM stack, including new integrations with HuggingFace 🤗 pipelines, asynchronous feedback management⌛, walkthrough🚶display of each component in your application's call stack, and emojis in the leaderboard! ✅ Check out the newest changes on GitHub.
Augmented information retrieval is growing as one of the most common applications of LLMs building on the success of new tools like LangChain, LlamaIndex and AutoGPT. Chaining together components into an LLM application is a straightforward way to bring new applications to life. However, the prevailing method for building augmented language model systems often feeds redundant prompts into the LLM at each reasoning step, and this redundancy only grows as these systems become more complex.
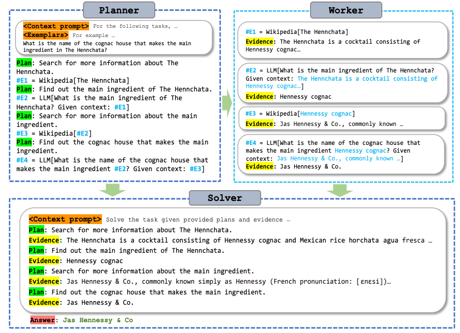
ReWOO (Reasoning WithOut Observation) detaches the reasoning process from external observations, thus significantly reducing token consumption, achieving 5x token efficiency on one benchmark. ReWOO makes its efficiency gains through its modular approach, using a plan-work-solve paradigm.
Planner composes a blueprint with an enumerated series of descriptions of work that must be done.
Worker enables ReWOO to interact with the environment through tool-calls. Once Planner provides a blueprint, designated Workers are invoked with instruction input, and populate the blueprint with real evidence or observations.
Solver processes all plans and evidence to formulate a solution to the original task or problem, such as providing answers in QA tasks or returning the work status for action requests.
Figure 1 from ReWOO paper demonstrating their new method’s three modular components for constructing augmented language models: Planner, Worker and Solver.
Less is More for Alignment
While ReWOO helps us build a more efficient LLM system, Less is More for Alignment (LIMA) gives us a more efficient model to use inside the system. LIMA demonstrates that given a strong pretrained language model, remarkably strong performance can be achieved by simply fine-tuning on 1,000 carefully curated training examples.
The researchers curated 750 top questions and answers from community forums, such as Stack Exchange and wikiHow, sampling for quality and diversity. In addition, they manually wrote 250 examples of prompts and responses, while optimizing for task diversity and emphasizing a uniform response style in the spirit of an AI assistant. LIMA, a pretrained 65B-parameter LLaMa model, was then fine-tuned on this set of 1,000 demonstrations.
Using evaluations from crowd workers, responses from LIMA were evaluated to be either equivalent or strictly preferred to GPT-4 in 43% of cases and as high as 58% when compared to Bard and 65% compared to DaVinci003, which was trained with human feedback.
In addition, the researchers measured the absolute performance on 50 random examples and found the performance to at least meet the requirements of the prompt in 88% of cases. They also identified 20 cases where the prompt was outside the distribution provided in the curated fine-tuning set, and LIMA performed passably on 80% of such cases. Likewise, they measured LIMA’s performance on 30 safety related prompts and found it to respond safely to 80% of them.
Through a number of follow-up experiments, the researchers point to two key factors for LIMA’s performance.
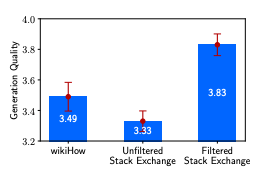
Diversity: The researchers found much greater performance when fine-tuning on a heterogeneous set of prompts (e.g., StackExchange) compared to a homogeneous set of prompts (e.g., WikiHow).
Quality: The researchers also compared an un-filtered random sample of StackExchange responses to a set filtered to only excellent responses. This high quality set of responses led to an even greater gain than that associated with diversity.
Figure 2 from LIMA paper comparing the impact of both prompt diversity and response quality in the training set on generation quality.
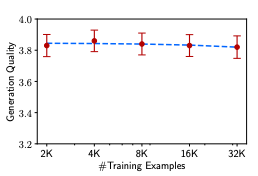
Quantity? While scaling up the number of examples is a well-known strategy for improving performance, doubling the training set did not improve LIMA’s response quality. This result, alongside the other findings, suggests that the scaling laws of alignment are not necessarily subject to quantity alone, but rather a function of prompt diversity while maintaining high quality responses.
Figure 3 from LIMA shows a flat relationship between the number of training examples and generation quality.
Want to dive deeper into papers like these? Join our slack community with leaders and practitioners of AI explainability in the AI Quality Forum community.
NVIDIA briefly became the sixth public company in the world valued at over $1 trillion largely because of its role in providing the GPUs that have driven the AI wave. NVIDIA plays the role of a classic “picks and shovels'' company by providing the underlying tools behind the innovation. This milestone is yet another signal that the demand for training and deploying new AI systems will only continue to grow.
However, the growing power of AI also raises concerns about the potential for misuse. In the same week as NVIDIA’s milestone, the Center for AI Safety released a statement warning that “mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.”
The statement was signed by a number of prominent AI researchers and figures, including OpenAI CEO Sam Altman, DeepMind co-founder Demis Hassabis, and Anthropic CEO Dario Amodei. The signatories called for a “concerted effort” to address the risks of AI, including developing new safety guidelines, funding research into AI safety, and educating the public about the potential risks.
The Center for AI Safety’s statement is a reminder that AI is a powerful technology with the potential to do great harm as well as great good. As AI continues to develop, it is essential that we take steps to mitigate the risks and ensure that AI is used for good.
As we mentioned in the opening paragraph, we’re doing our part by building TruLens in the open source community to help AI developers improve the quality and safety of their LLM experiments. Want to support both this work and the open source community as a whole? We’d love it if you gave TruLens a star on GitHub 🤩.