The Latest in Trustworthy ML Research and Practice
Trust Issues
May 18, 2023 • Epoch 8
Have you kicked the tires on our free Diagnostics release yet? We’re about a month into the open beta release and we’re seeing lots of exciting engagement as users weave greater AI quality into their tabular ML models. Data scientists and ML engineers in any industry from e-commerce to health and everything in between stand to benefit from greater performance, stability, fairness and explainability for their models. We hope you give it a try!
This month, we read two papers about power law analysis for scaling LLMs. What is the motivation behind studying LLMs scaling? Since LLMs are becoming progressively larger, running many experiments while changing the number of training tokens, the model size, or the available compute is not feasible. To guide LLM developers in selecting these variables, authors studying LLM scaling have proposed to use power laws to model LLM performance as a function of either number of training tokens (D), model size (N), or training compute (C). This way, the final loss of the LLM at a given budget can be predicted, allowing the developer to run a single training run rather than a whole battery of them!
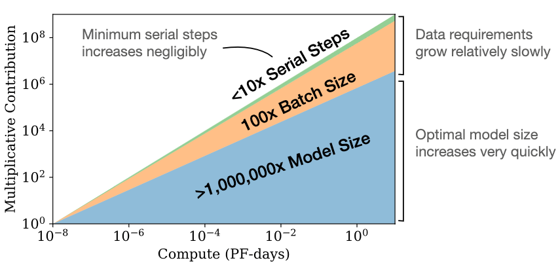
Getting back to the papers in question – the first paper, from OpenAI, claims that training LLMs to convergence (i.e., taking enough training steps until the loss levels off) is inefficient. For a fixed value of C, they recommend “stopping significantly short of convergence” and instead recommend focusing on scaling N. Additionally, the authors study the optimal batch size for models at a given size.
Figure 3 from OpenAI paper demonstrating the recommended rate of scaling model size, batch size, and number of training iterations as a function of available compute.
The second paper, from Deepmind, alternatively suggests that for the same compute budget a smaller model trained on more data will perform better. They test this hypothesis by training Chinchilla (70B parameters) outperforms Gopher (280B parameters) on a number of different quality metrics. The authors based the size of Chinchilla (N=70B) and the number of training tokens (D=1.4T tokens) by varying N, D, and C of Gopher based on an optimal model scaling framework. This framework recommends scaling N and D in roughly equal proportions for increasing values of C.
Table 3 from the DeepMind paper outlining their proposed optimal number of parameters (N) and training tokens (D) at different compute budgets/FLOPs (C).
Interestingly, these two papers recommend focusing on scaling of different parameters while developing LLMs. As mentioned above, the OpenAI paper recommends scaling the model size (N), while the DeepMind paper recommends placing more attention on scaling the number of tokens (D). The DeepMind authors do note that scaling of data does present issues, such as contamination of training data with test data and safety concerns, such as toxicity, bias, and data privacy.
Lowering model size for adaptation 📉
As the models themselves get larger and larger, fine-tuning can become prohibitively expensive. Researchers from Microsoft have proposed Low-Rank Adaptation (LoRA) which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture. Hypothesizing that the change in weights during model adaptation also has a low “intrinsic rank”, LoRA allows the training of some dense layers in a neural network indirectly by optimizing rank decomposition matrices of the dense layers’ change during adaptation.
This low-rank adaptation matrix amplifies the important features for specific downstream tasks that were learned but not emphasized in the general pre-training model. Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times; all with similar or better model quality compared to fine-tuning and without introducing inference latency.
Want to dive deeper into papers like these? Join us for the next session of our paper reading group (join here), or discuss with leaders and practitioners of AI explainability in the AI Quality Forum community.
Open source, high quality large language models are cheaper and more adaptable than ever - and these models are enabled by research originating from the large players themselves. Compute optimal models (i.e., Deepmind’s Chinchilla) allows for less computation for fine-tuning and inference. Meanwhile, Low Rank Adaptation (LoRA) from Microsoft reduces the number of parameters and GPU memory requirement, additionally facilitating low-cost public involvement.
Public access to sufficiently high-quality models has kicked off a ton of open source iteration and excitement, including new models like Dolly and the self-aligned Dromedary, new fine-tuned models StarCoder, and limitless new applications built on top of langchain. As at least one Google researcher noted in a leaked internal document, open source LLM development may soon out-compete the monoliths in the same way Stable Diffusion outpaced DALL-E in image generation. The researcher lists three key reasons for their lack of moat around LLM development:
No secret sauce
Free open source models are comparable in quality
Development of giant models is slow and inhibits iteration
OpenAI’s Sam Altman testified before the U.S. Senate this week about the need to regulate AI development, even going as far as suggesting a licensing scheme. Licensing or similar regulation would add a barrier to entry, essentially building a moat for the incumbents. While some protection against the potential harms of AI is needed, licensing requirements could slow down the frontier of development, including development of the very guardrails that Altman calls for. Instead, harsher penalties for AI applications that bring harm to consumers may serve as better protection.
It can be easy to feel left behind by the rapid pace of the AI frontier, but we’re here to heIp. If you want to support Trust Issues, please share it with any friends, colleagues and family that would enjoy it. Subscribe or visit our archive using the link👇 below.