The Latest in Trustworthy ML Research and Practice
Trust Issues
March 9, 2023 • Epoch 6
Old data science techniques are being called into question, and the FTC is calling out baseless claims of AI. At the same time, we have new ways to explain image models and we can now ask AI questions about images. This issue dives into all of it, along with ChatGPT’s new API.
It can be easy to feel left behind by the rapid pace of the AI frontier, but we’re here to help. If you want to support Trust Issues, please share it with any friends, colleagues and family that would enjoy it. Anyone can subscribe using the link👇 below.
In the post-ChatGPT era, you have undoubtedly heard the discourse around large language models (LLMs) - neural network models with billions (or even trillions!) of parameters which take in natural language as their inputs to perform a variety of downstream tasks. Neural networks are not restricted to just text inputs. Such models are used extensively (and effectively) on other input domains such as image, audio, and tabular data.
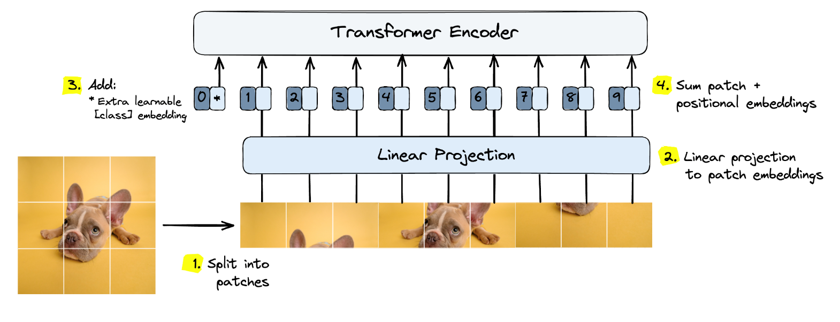
Transformer-based models can handle any input data type so long as it can be converted into an embedding, which is a continuous-valued vector. Vision transformers (ViTs) differ from those used for text input in that instead of embedding of tokenized words, we use embeddings of linearly projected patches and their positions, where patches are just pieces of the image.
Figure 1 from Pinecone.io, Vision Transformers (ViT) Explained
The Shapley approach involves holding out sets of patches and evaluating the model with only partial information (i.e., without the held-out set) to identify influential image patches. Because Shapley value calculation scales exponentially with the number of inputs, they are traditionally estimated using sampling techniques, such as in KernelSHAP - however these methods often still require hundreds or thousands of evaluations to explain a single prediction.
Researchers out of the University of Washington take a learning based approach to estimate these Shapley values, dubbed ViT Shapley. To do so, they train a new ViT with a loss function that encourages feature scores that provide an additive explanation for each prediction - notably, training without the ground truth Shapley values as supervision. Instead of training from scratch, the researchers fine-tuned a pre-trained ViT model, such as the original classifier. Using insertion and deletion as the primary evaluation metrics, ViT Shapley outperforms alternative methods (SmoothGrad, GradCam, Attention Rollout, etc.) on the Imagenette and MURA datasets; meaning that ViT Shapley more quickly identified important patches that drive the prediction towards a certain class, and that quickly reduce the prediction probability when deleted.
As we mentioned above, neural networks can be used for a variety of input data types - and now they can be used for multiple data types at once. Observing this potential for neural networks, researchers from Microsoft published a paper proposing a multimodal large language model (MLLM).
Figure 2 from “Language Is Not All You Need: Aligning Perception with Language Models” showing examples of multimodal prompts with both text and images.
To encode multimodal prompts into embeddings, the authors use two different encoding schemes: a look-up table for text-based tokens and a visual encoder for continuous valued signals (i.e., images). The resulting embeddings are passed into a decoder, which produces a text output based on the given task.
What does explainability look like for these new multimodal models? Output explanations should likely include both highlighted tokens in the text prompt and influential patches from the input image - and we’d love to see this in action.
Want to dive deeper into papers like these? Join us for the next session of our paper reading group (join here), or discuss with leaders and practitioners of AI explainability in the AI Quality Forum community.
The reproducibility crisis has found its way to genetics through a technique that’s been around for more than 100 years, Principal Component Analysis or PCA. A new paper out of Sweden carried out an extensive empirical evaluation of PCA, a popular black-box technique for reducing the dimensionality of high-dimension data. Using standard PCA applications from the literature, the team modulated the parameters of the application (choice of populations, sample sizes, and, in one case, the selection of markers). In doing so, the researchers were able to easily manipulate the outcome, suggesting that PCA results are not as reliable, robust or replicable as the field assumes.
In the news 📰
The FTC is stepping in to keep unjustified AI claims in check. The agency specifically calls out exaggerated claims, comparative claims against non-AI products, and baseless claims of using AI at all. They also doubled down on their earlier warning of the risks associated with AI technology, stating that not understanding the “black box” or not knowing how to test it is not a sufficient defense.
OpenAI has released an API for GPT-3.5 turbo, the model that powers ChatGPT. Charging only two cents per ten thousand tokens, Snap, Quizlet, Instacart and Shopify are among the early adopters - and this undoubtedly will proliferate the advance of new AI-powered startups and applications. Despite the pressure, businesses should be sure to understand and test the model for their application before releasing in production. By abstracting away the original interface, businesses may imply unwarranted trust in these models - and as we read above, regulators are taking note.
Thanks for reading Trust Issues. By the way, take a look at our new whitepaper on AI Quality: A guide to understanding and managing AI performance, operationalization, and impact. 👇👇👇