The Latest in Trustworthy AI Research and Practice
Trust Issues
November 9, 2023 • Epoch 14
Welcome to epoch 14. In this issue, we explore more efficient methods for alignment, the reliability of LLMs as judges, and the US executive order on AI. We conclude with a recap of OpenAI Dev Day.
If you’d like to join our monthly reading group and discuss the frontier of AI research, including papers like these, you can sign up here:
Efficiently aligning LLMs with human preferences via direct preference optimization
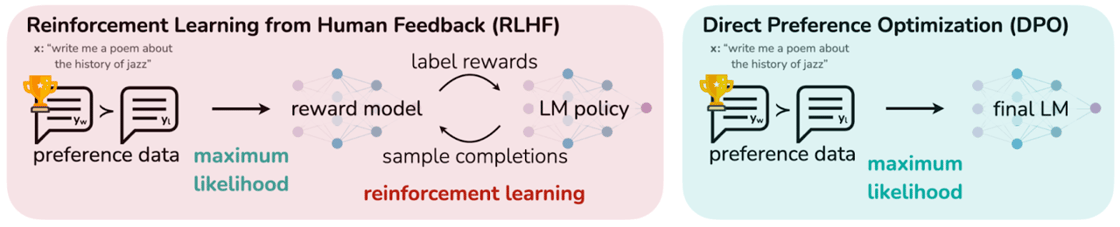
Reinforcement learning from human feedback (RLHF) is the de facto standard for aligning large language models (LLM) with human preferences. RLHF generally involves three steps:
Supervised fine-tuning (SFT): Start with an LLM that is pre-trained on a particular downstream task (e.g., dialogue, summarization, etc.)
Reward modeling: Using human annotated preference data (i.e., prompt-response pairs) from the LLM from the SFT step, train a reward model in a binary classification framework (i.e., answer the question: “For a given prompt, is response A better than response B?”).
Reinforcement learning (RL) fine-tuning: With the reward model, fine-tune the LLM from the SFT step in a reinforcement learning framework. The loss function here tries to:
Maximize the reward (as modeled by the reward model)
Minimize the KL-divergence between the LLM’s latest policy and a “reference” policy (i.e., the original policy of the LLM from the SFT step).
While RLHF has found massive success in LLM alignment, the reward modeling step can be construed as extraneous to the downstream task of the LLM, and this is the observation that motivates Direct Preference Optimization (DPO), a paper by researchers from Stanford.
Figure 1. Illustration of differences between RLHF and DPO. Both methods assume a supervised fine-tuned language model is available. RLHF involves a two-step process of 1) training a reward model using preference data then 2) using reinforcement learning to train the LLM. In contrast, DPO uses preference data to directly train the LLM (i.e., no reward model is necessary).
In the paper, the authors analytically derive a new loss function that directly uses preference data to fine-tune the LLM. They derive this new loss function by showing that the RL loss function (described in step 3 above) can be expressed solely in terms of the LLM policy without using the output of a reward model’s output.
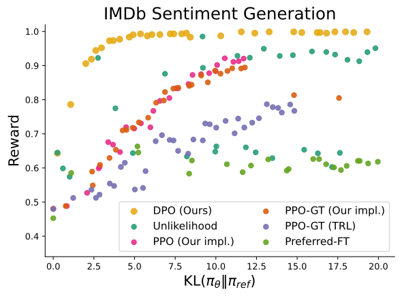
Figure 2. A comparison of the reward frontiers (reward vs. KL divergence between fine-tuned/reference policy) for DPO and other benchmark algorithms for fine-tuning LLMs using preference data.
The authors conducted experiments to assess the quality of DPO-trained LLMs. Figure 2 shows the results of one such experiment, controlled sentiment generation on an IMDb dataset. In this experiment, they fine-tuned a pre-trained GPT-2-large to take the beginning of a movie review as a prompt and to generate a positive review as a response. Looking at Figure 2, DPO is able to achieve the highest reward across the majority of KL values.
Are language models reliable judges?
Large language models (LLMs) are powerful AI systems that can generate realistic text and images for various tasks. But how can we evaluate their quality and reliability in open-ended scenarios? A new paper from Korea University and Microsoft Research proposes to fine-tune LLMs as scalable judges (JudgeLM) that can assess the outputs of other LLMs.
JudgeLM is trained on a large-scale dataset of task seeds, LLMs-generated answers, and GPT-4-generated judgments. In generating this data, the authors introduce swap augmentation, reference support and reference drop to improve evaluation robustness.
Figure 3. Data generation pipeline for JudgeLM.
Swap augmentation - to mitigate position bias, add additional examples where the answers are swapped. This helps the model focus more on the contents of answers rather than the positions.
Reference Support - analogous to evaluating context-augmented QA tasks (such as RAGs), they provide reference answers for use by JudgeLM in evaluation.
Reference Drop - to alleviate overfitting for fine-tuning formats (such as the inclusion of references), the authors randomly drop the training sample with reference. This improves the ability of JudgeLM to give fair evaluations with or without reference.
The paper shows that JudgeLM achieves state-of-the-art performance and high agreement with the teacher judge on two benchmarks, and demonstrates its extended capabilities in judging various tasks. Importantly, it introduces three techniques that prove useful for improving the reliability of LLM-based evaluations while providing evidence that fine-tuned LLMs on an evaluation task can be reliable judges.
Executive order on safe, secure, and trustworthy AI
The order outlines eight principles and priorities which inform its policies and guidelines, including:
Ensuring the safety and security of AI systems, with particular emphasis on biotechnology, cybersecurity, critical infrastructure, and national security threats.
Promoting responsible innovation, competition, and collaboration in AI development to solve the most pressing problems in the U.S.
Remaining committed to supporting American workers by ensuring that workers’ rights are bolstered rather than undermined by AI systems
Advancing equity, civil rights and civil liberties, particularly in hiring, housing, and healthcare,
Protecting consumers in accordance with existing consumer protection laws to reduce fraud, bias, and discrimination
Ensuring privacy by requiring AI developers to lawfully and securely collect, use, and retain user data
Improving the Federal Government’s ability to regulate, govern, and support responsible AI usage by attracting, retaining, and developing AI professionals
Leading global progress in AI development with an emphasis on pioneering, building, and promoting safeguards on AI systems to ensure responsible deployment
The executive order directs federal agencies to establish guidelines and policies pertaining to generative AI. For example, the order directs the Secretaries of Commerce, Energy, and Homeland Security along with the Director of the National Institute of Standards (NIST) to establish federal procedures for red-teaming tests of foundation models.
Additionally, the order recommends Federal Government investments in and funding for industries and initiatives relevant to AI, including:
Semiconductor firms to develop and manufacture the hardware necessary for AI
Professional-development programs and courses on AI and related disciplines for Federal employees
Overall, the executive order places a heavy emphasis on clear and present risks of generative AI, like cybersecurity of critical infrastructure, misinformation, and CBRN defense. As Shameek Kundu (Head of Financial Services at TruEra) describes it, this emphasis on current dangers is a “pragmatic assertion” of how much work there remains before addressing the existential, relatively far off problems (e.g., AGI).
For additional analysis of the executive order, read our blog post on Key Takeaways and Recommendations (written by Will Uppington, CEO at TruEra).
OpenAI Dev Day recap
The shot heard around the AI world was the death of GPT “thin-wrapper” companies with the introduction of the assistants API that can handle tasks such as retrieval on user-uploaded data. They also introduced GPT-4 Turbo with a best-in-market 128K context window. In combination, these may eat away some of the market share controlled by RAGs. However RAG-based applications provide a substantial benefit beyond “naive chat with your data” through their flexibility in (retrieval methods, indexing strategies, etc) and agnostic nature (you are not tied to one LLM provider).
Perhaps the most underrated announcement of the event was features to improve the quality and reproducibility of LLM applications. For function calling, they quietly announced the ability to run more than one function with a single call, e.g. “Roll up the windows and turn on the A/C”. This is also known as parallel function calling. They also suggest that they improved the accuracy of function calling, however we are not aware of any evidence to support this claim.
Both GPT-3.5 Turbo and GPT-4 Turbo now include a new JSON mode that can be implemented outside of function calling. The new API parameter response_format enables the model to constrain its output to generate a syntactically correct JSON object.
Last, a new seed parameter enables reproducible outputs by making the model return consistent completions most of the time. This feature is particularly useful for identifying and recreating failure modes for LLM apps, and writing more comprehensive unit tests.
Do you find value in receiving this monthly newsletter? If you want to support Trust Issues, we’d appreciate it if you shared it with any friends, colleagues and family that would enjoy it. Anyone can subscribe or visit our archive using the link👇 below.
Interested in LLM Observability? Join TruEra's webinar on LLM Observability: the Why, What and How on Dec 6th. This month's webinar features an all-star panel including Google, Snowflake, TruEra and Wing Venture Capital.