Figure 1. Chain of density prompt and resulting improvement in quality
Because this is such an important task for LLM app observability, we also built summarization quality evals into open-source TruLens. For this evaluation, we use a different approach – called chain of thought prompting – to allow the LLM to carefully identify the key points from the source and check to make sure each is included in the resulting app response.
Mistral 7B model achieves SOTA
Mistral 7B is the latest LLM to make a splash in open-source with a new SOTA boasting. Even better – they’ve released it with a permissive Apache 2.0 license so it can be used without restrictions.
- Outperforms Llama 2 13B on all benchmarks
- Outperforms Llama 1 34B on many benchmarks
- Approaches CodeLlama 7B performance on code, while remaining good at English tasks
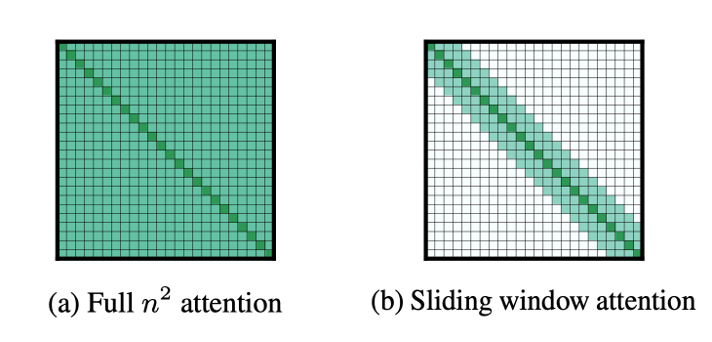
How did they do it? One key advancement that the Mistral 7B used is Sliding Window Attention to handle longer sequences of tokens at a lower cost.
That’s a lot of jargon - let’s break it down.
Sliding window attention
Sliding window attention is an approach pioneered by a pair of recent papers (1, 2) that improves upon self-attention. While self-attention can be extremely powerful in capturing contextual information, it relies on the entire sequence. This can be quite expensive as the sequence grows.
On the other hand, sliding window attention (compared below) relies on only a recent window of tokens to build contextual representations of the entire context.