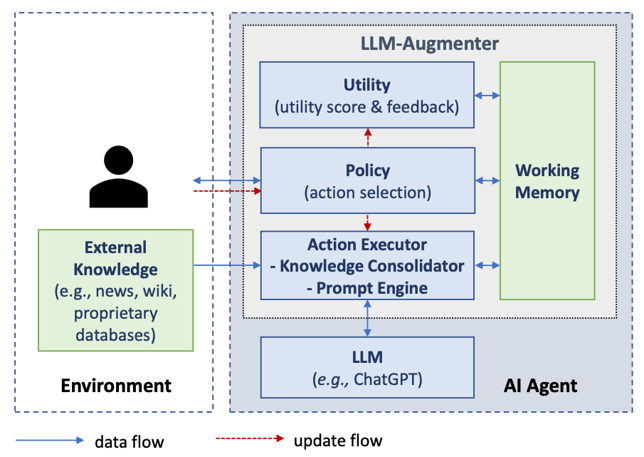
Figure 3. The architecture of the LLM-Augmenter proposed
in the paper Check Your Facts and Try Again
By providing these evaluations back to the LLM, the LLM-Augmenter significantly reduced hallucinations compared to ChatGPT without sacrificing the fluency and informativeness of the response. As we continue to build out LLM applications, we should consider incorporating evaluations not only for observability, but as a mechanism for improving output quality itself as the researchers do here.
OpenAI fine-tuning announced
OpenAI continues to lead the way in growing the adoption of LLMs, recently announcing the availability of GPT-3.5 turbo fine-tuning. At a high level, fine-tuning improves on few-shot learning by training on many more examples than can fit in the prompt. After the model has been fine-tuned, you can achieve better results on tasks similar to the examples you’ve fine-tuned to while providing fewer examples in prompts. Ultimately, this can work to reduce the cost and latency of your LLM app.
Importantly, fine-tuning is not a replacement for retrieval methods, and is instead best for style changes and learning new tasks that are not easily described in words. Even with fine-tuning, the principle of allowing other components of your app to handle memorization still applies.
Federal AI licensing
In response to the glut of companies seeking to develop LLMs, the Center for AI Policy has outlined policy recommendations to “[ensure] safety in the development of AI that is advanced enough to pose major threats to public safety or international security.” These recommendations include the establishment of a federal agency that would regulate so-called “frontier AI” development, which includes any ML models that meet one of the following conditions:
- Uses at least 10^24 FLOPs during training
- Has at least 80B parameters
- Costs at least $10M to train
- Achieves at least 70% on MMLU or 1300 on the SAT
Current examples of such frontier AI include GPT-4, PaLM 2, and Claude 2. The proposed agency would be granted oversight on firms engaged in frontier research, as they would be able to monitor and license the stockpiling of large AI hardware clusters, the deployment/development of frontier AI systems, and access to frontier AI model weights.
While the risks around LLMs and the need for regulations around them have been enumerated in many places, the specific parameters of this proposal have been met with scrutiny. Reading the comments on the CAIP announcement post by Thomas Larsen (the Center’s Executive Director), developers are concerned that the conditions defining “frontier AI” described above might encompass firms that are not even working with generative LLMs (e.g., SOTA image classifiers, self-driving cars, healthcare applications, etc.). Some have even noted that the proposed performance/cost thresholds already capture the open source Llama 2 model, which many LLM developers are fine-tuning for their own applications.
Whatever the ultimate parameters of these thresholds are, policy makers should strive to craft regulations that do not hamstring open source work and academic research into LLMs. Doing so may cause more harm than good.