Figure 1. Image from Zou, et al.
Notably - by generating adversarial examples to fool both Vicuna-7B and Vicuna-13b simultaneously, the researchers found adversarial examples also transferred to Pythia, Falcon, Guanaco, and surprisingly, to GPT-3.5 (87.9%) and GPT-4 (53.6%), PaLM-2 (66%), and Claude-2 (2.1%).
The right to be forgotten (by LLMs)
Given the large swathes of data that LLMs are trained on, it is difficult to prevent them from learning personal information about private individuals, and research has shown that such personal information can be extracted from publicly available LLMs using novel attacks. This raises legal questions, such as “What responsibilities do LLM developers have in protecting the privacy of individuals?” as well as technical questions such as “What can LLM developers do to protect privacy?”
Legal questions such as this are the focus of the “Right to be Forgotten in the Era of Large Language Models” paper by researchers from CSIRO’s Data 61 and the Australian National University. As its title suggests, the paper focuses on the Right to be Forgotten (RTBF), a legal principle established based on a ruling by the National High Court of Spain in Google Spain SL v. Agencia Española de Protección de Datos.
In the case, the Court declared that “controllers” of personal data (in this case, “Google”) are required to remove personal information published by third parties. By the authors’ account, this decision is rooted in the notion that citizens are entitled to the human right of Privacy, as enshrined in both primary law (Article 8 of the EU’s charter) as well as secondary law (the GDPR and Directive 95/46).
Noting that companies like Google are concerned with how LLMs will be utilized in search, the authors maintain that developers of LLMs will have similar duties to uphold the RTBF. Importantly, they outline some of the unique privacy challenges that LLMs present, including users’ chat histories (which will likely include personal information) and model leakage of personal data (which can be embedded in the model during training and exposed when prompting). These challenges can inhibit the privacy rights of users, including the right to access their data, the right to have their data erased, and the right to have their data rectified.
While LLMs present new challenges in respecting the privacy rights of users, the authors suggest two categories of approaches to making LLMs conform to the RTBF: either by fixing the original model or by applying so-called “band-aid” approaches. In the following section, we discuss an approach belonging to the former category.
Machine unlearning
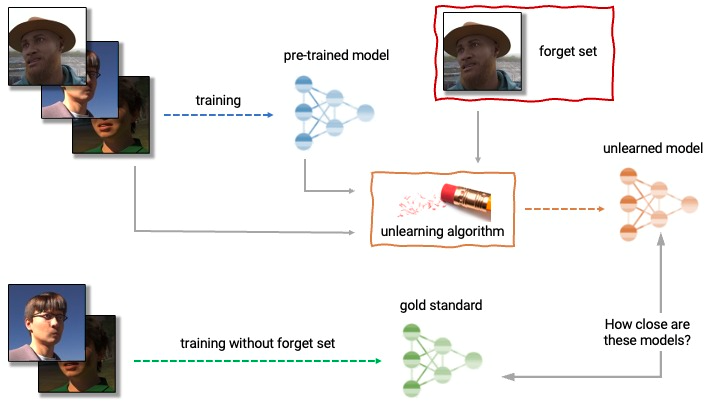
The field of machine unlearning is one approach to addressing RTBF. While removing data from back-end databases should be straightforward, it is not sufficient as AI models often 'remember' the old data. Not only is old data ‘remembered,’ but sensitive training data can even be revealed by some adversarial attacks, as was the case for NVIDIA. Unfortunately, the cost of training the large models of today is such that it’s cost prohibitive to retrain each time data is removed. Machine unlearning provides one avenue to remove this sensitive data from the model without the high cost of retraining.
An unlearning algorithm takes as input a pre-trained model and one or more samples from the train set to unlearn (the "forget set"). From the model, forget set, and retain set, the unlearning algorithm produces an updated model. An ideal unlearning algorithm produces a model that is indistinguishable from the model trained without the forget set.