The Latest in Trustworthy AI Research and Practice
Trust Issues
July 13, 2023 • Epoch 10
In this month’s Trust Issues, we dive deep into recent research aimed at improving the quality of LLM responses, including retrieval augmented generation and data importance evaluation. We also discuss some recent news in the LLM space, like Harvard’s decision to use LLMs as teaching assistants and the reported decline in ChatGPT’s usage.
Making LLMs more grounded
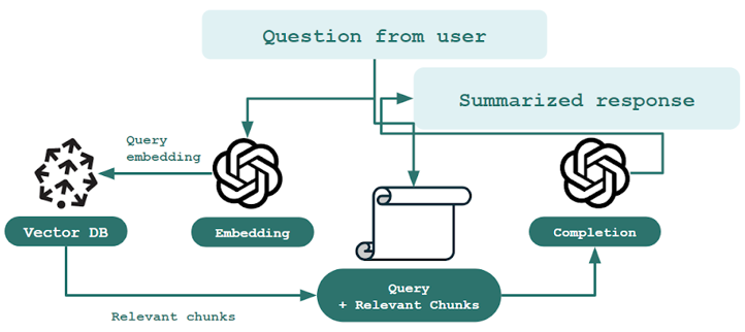
Retrieval Augmented Generation (RAG) is an emerging paradigm that augments LLMs with a knowledge base to mitigate model hallucination, one of the most talked about issues with LLMs. In the RAG paradigm, rather than just passing a user question directly to a language model, the system "retrieves" any documents that could be relevant in answering the question from the knowledge base, and then passes those documents (along with the original question) to the language model to generate the final response.
In this process, a numerical vector (an embedding) is calculated for all documents, and those vectors are then often stored in a vector database (a database optimized for storing and querying vectors). Incoming queries are then vectorized as well (typically using an LLM to convert the query into an embedding). The query embedding is then matched against the document embeddings in the vector database to retrieve the documents that are most similar to the query.
Figure 1: architecture of a typical retrieval augmented generation application
Improving retrieval augmented generation
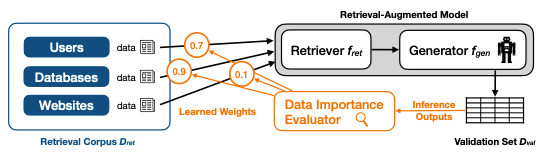
On top of RAG, Lyu et al. have proposed data importance evaluation as a method for boosting performance of this style of application. The researchers propose the computation of weights based on the performance on a validation set. Those weights are then used to reweight or prune the data sources and improve the application’s performance.
Figure 2 showing the addition of data importance evaluation into a retrieval augmented LLM application.
For question answering, the researchers focused on two benchmarks from the WikiFact dataset: restaurant, where the city column of a table about restaurants must be inferred, and buy, where the manufacturer of electronics products must be imputed. These datasets are then split into validation and test datasets, and the validation is used to compute the data importance weights.
On the restaurant and buy benchmarks, data importance evaluation & pruning increased the mean accuracy of GPT-JT (an open source fork of GPT-J trained using a decentralized training algorithm) from 33.3% to 37.7%, outperforming GPT-3.5. Along with the paper, the researchers also released an open source repository and pip package, called ragbooster.
While promising, only two relatively straight forward benchmarks are used - more work needs to be done to see if it can be useful for more complex applications. However even if the underlying algorithm for reweighting does not extend to more complex use cases, the theme still applies. Data quality, as we talked about in the last issue, is a critical component for building performant LLMs and LLM-based applications.
Evaluation and tracking of retrieval augmentation generation is one of the core use cases for which we built TruLens. Curious to see if data importance evaluation, or other methodological changes can improve the performance of your LLM application? We’d love it if you gave TruLens a spin, and if you’re feeling generous, a star on GitHub 🤩.
Along the same theme, a new paper out of Microsoft Research entitled Textbooks Are All You Need doubles down on data quality, specifically focused on coding tasks and writing simple python functions and their docstrings. By crafting “textbook quality” data using off-the-shelf LLMs, the researchers were able to train a model that surpasses almost all open-source models on coding benchmarks such as HumanEval and MBPP despite being 10x smaller in model size and 100x smaller in dataset size.
Building on prior work from Meta, the authors leverage diversity of data to build strong training and fine-tuning sets. In building their data, they aim to synthesize examples covering a wide range of coding concepts, skills, and scenarios, and that they should vary in their level of difficulty, complexity, and style.
The synthetic textbook dataset constructed consists of less than 1 billion tokens of GPT-3.5 generated Python textbooks, synthesized to provide a high-quality source of natural language heavy text interleaved with relevant code snippets. For alignment, a CodeExercises dataset is generated also using GPT-3.5, consisting of less than 180 million tokens of Python exercises and solutions. Each exercise is a docstring of a function that needs to be completed.
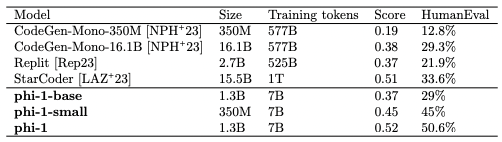
Phi-1, the model that was both trained on the synthetic textbook data and aligned using CodeExercises outperforms CodGen, Replit and StarCoder. For reference, phi-1 small uses the same training pipeline as phi-1 but only trains 350M parameters, and phi-1-base is the unaligned model.
Figure 3 from Textbooks Are All You Need showing the performance of phi-1 against CodeGen, Replit and StarCoder.
The performance of phi-1 is notable largely because it gives us further confirmation that we can achieve performant LLMs with smaller, high quality data - especially for narrow tasks such as code generation. Interestingly, phi-1 also had remarkable chat capability even though chat data was only used in pre-training and not in fine-tuning. Below is one such example and a foreshadowing of Harvard’s plans for their popular introductory computer science course.
Figure 4 from Textbooks Are All You Need: phi-1 as a teaching assistant answering a question about pyplot.
LLMs as teaching assistants
The Harvard offering of CS50, an introductory computer science course that is also offered publicly online via edX, will use its own custom LLM as a teaching assistant (TA). David Malan, the professor of the CS50, gave his rationale for integrating LLMs as a teaching tool. Firstly, students have always adopted new software tools to help them navigate courses, and utilized appropriately, LLMs can be just such a tool. Importantly, Malan and the teaching staff plan to develop their own LLM that will help be more pedagogically sound than off-the-shelf models. For example, the “CS50 Bot” will guide students towards answers and encourage them to think critically rather than simply handing them fully-formed answers.
An additional reason for adopting LLMs is one of scale. Large introductory lectures are almost always plagued by manpower issues – a single professor is typically responsible for organizing the course and giving lectures, and then a small team of underpaid and overworked TAs is tasked with holding recitations, grading assignments/exams, and providing one-on-one help to students. Since CS50 is offered to a massive online audience, scaling up personalized help for students is even more challenging. One goal of using a language model as a TA is to provide a better experience to both the TAs (to help lessen the workload placed on them) and to the students (to improve the course’s accessibility by providing them with more immediate help and feedback on their work).
However, this move towards automating some of the functions of TAs comes at a time when graduate students are actively fighting for fairer wages and better working conditions, and historically, new automation technologies have displaced workers and depressed their wages. This potential adverse outcome is a focal point for the ongoing Writer’s Guild strike, which is fighting against the adoption of LLMs in television and movie script writing. Hopefully, the adoption of language models as TAs in CS50 can be a template of how automation can be used to empower graduate students to better serve students rather than an excuse to devalue their labor.
ChatGPT usage declines
In other LLM news, ChatGPT’s user base saw the first decline in monthly usage since the model’s public release back in March 2023. Despite reaching 100 million new users in its first two months, ChatGPT’s aggregate traffic decreased by 10 percent from May to June.
One reason for this decline in usage could be a seasonal trend – with most undergraduates on summer break, a large segment of ChatGPT users are taking a vacation from using the model to help them on their coursework.
Another reason for declining usage is more of an intrinsic problem – some users have expressed dissatisfaction with the increasing number of model guardrails being put in place on the model. For example, ChatGPT is trained to “refuse'' certain user prompts (e.g., the model may respond with, “I’m sorry, but as a language model, I cannot answer that question”), and while guardrails on models are necessary to mitigate potential misuse and harm, some users see such safety measures as unnecessary censorship which ultimately undercut the model’s utility.
Whether it is to avoid guardrails or for other reasons, LLM users have never had more options available to them. Larger tech firms like Google (with Bard) and Meta (with LLaMA) have publicly available APIs for their proprietary LLMs as do smaller firms like Anthropic (with Claude) and HuggingFace (with BLOOM, which is open source). Moreover, different LLM users are seeking out models that are more tailored to their specific applications, including RAG on enterprise data or automated teaching assistants as discussed earlier in this newsletter. With this variety of use cases, it is not shocking that ChatGPT has seen a decline in usage as developers seek out LLMs that are more customizable.
Do you find value in receiving this monthly newsletter? If you want to support Trust Issues, we’d appreciate it if you shared it with any friends, colleagues and family that would enjoy it. Anyone subscribe or visit our archive using the link👇 below.